import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap from sklearn import datasets
# Set the format of labels defLabelFormat(plt): ax = plt.gca() plt.tick_params(labelsize=14) labels = ax.get_xticklabels() + ax.get_yticklabels() [label.set_fontname('Times New Roman') for label in labels] font = {'family': 'Times New Roman', 'weight': 'normal', 'size': 16, } return font
defPolynomial_regression_normal_equation(train_data, train_target, test_data, test_target): # the 1st column is 1 i.e., x_0=1 X = np.ones([np.size(train_data, 0), 1]) X_test = np.ones([np.size(test_data, 0), 1]) # Here to change M !!!!!!! M = 2
for i in range(1, M + 1): temp = train_data ** i temp_test = test_data ** i X = np.concatenate((X, temp), axis=1) X_test = np.concatenate((X_test, temp_test), axis=1) # X is a 10*M-dim matrix
# Normal equation w_bar = np.matmul(np.linalg.pinv(np.matmul(X.T, X)), np.matmul(X.T, train_target))
if __name__ == '__main__': # keep the same random training data seed_num = 100 np.random.seed(seed_num) # 10 training data train_data = np.random.uniform(0, 1, (10, 1)) train_data = np.sort(train_data, axis=0)
import numpy as np import matplotlib.pyplot as plt
# Set the format of labels defLabelFormat(plt): ax = plt.gca() plt.tick_params(labelsize=14) labels = ax.get_xticklabels() + ax.get_yticklabels() [label.set_fontname('Times New Roman') for label in labels] font = {'family': 'Times New Roman', 'weight': 'normal', 'size': 16, } return font
defPolynomial_regression_normal_equation(train_data, train_target, cv_data, cv_target,test_data,M): # the 1st column is 1 i.e., x_0=1 X = np.ones([np.size(train_data, 0), 1]) X_cv = np.ones([np.size(cv_data, 0), 1]) X_test = np.ones([np.size(test_data, 0), 1])
for i in range(1, M + 1): temp = train_data ** i temp_cv = cv_data ** i temp_test = test_data ** i X = np.concatenate((X, temp), axis=1) X_cv = np.concatenate((X_cv, temp_cv), axis=1) X_test = np.concatenate((X_test, temp_test), axis=1) # X is a 10*M-dim matrix
# Normal equation w_bar = np.matmul(np.linalg.pinv(np.matmul(X.T, X)), np.matmul(X.T, train_target))
# testing data test_data = np.linspace(0, 1, 100).reshape(100, 1)
M=9+1 E_train=np.zeros((M,1)) E_cv=np.zeros((M,1)) # change M for i in range(M): y_predict_test,y_predict_cv, E_train[i], E_cv[i] = Polynomial_regression_normal_equation(train_data, train_target, cv_data, cv_target,test_data, i)
import numpy as np import matplotlib.pyplot as plt
# Set the format of labels defLabelFormat(plt): ax = plt.gca() plt.tick_params(labelsize=14) labels = ax.get_xticklabels() + ax.get_yticklabels() [label.set_fontname('Times New Roman') for label in labels] font = {'family': 'Times New Roman', 'weight': 'normal', 'size': 16, } return font
defPolynomial_regression_normal_equation(train_data, train_target, cv_data, cv_target,test_data,M): # the 1st column is 1 i.e., x_0=1 X = np.ones([np.size(train_data, 0), 1]) X_cv = np.ones([np.size(cv_data, 0), 1]) X_test = np.ones([np.size(test_data, 0), 1]) # Here to change lambda Lambda=1e-12 I0= np.eye(M+1) I0[0]=0
for i in range(1, M + 1): temp = train_data ** i temp_cv = cv_data ** i temp_test = test_data ** i X = np.concatenate((X, temp), axis=1) X_cv = np.concatenate((X_cv, temp_cv), axis=1) X_test = np.concatenate((X_test, temp_test), axis=1) # X is a 10*M-dim matrix
# Normal equation w_bar = np.matmul(np.linalg.pinv(np.matmul(X.T, X)+Lambda*I0), np.matmul(X.T, train_target))
import numpy as np import matplotlib.pyplot as plt
# Set the format of labels defLabelFormat(plt): ax = plt.gca() plt.tick_params(labelsize=14) labels = ax.get_xticklabels() + ax.get_yticklabels() [label.set_fontname('Times New Roman') for label in labels] font = {'family': 'Times New Roman', 'weight': 'normal', 'size': 16, } return font
defPolynomial_regression_normal_equation(train_data, train_target,test_data,M): # the 1st column is 1 i.e., x_0=1 X = np.ones([np.size(train_data, 0), 1]) X_test = np.ones([np.size(test_data, 0), 1]) # Here to change lambda Lambda=1e-8 I0= np.eye(M+1) I0[0]=0
for i in range(1, M + 1): temp = train_data ** i temp_test = test_data ** i X = np.concatenate((X, temp), axis=1) X_test = np.concatenate((X_test, temp_test), axis=1) # X is a 10*M-dim matrix
# Normal equation w_bar = np.matmul(np.linalg.pinv(np.matmul(X.T, X)+Lambda*I0), np.matmul(X.T, train_target))
# Set the labels font = LabelFormat(plt) plt.xlabel('x', font) plt.ylabel('y', font) plt.legend(['True model', 'Predicted model,$M=9,\lambda=10^{-3}$'])
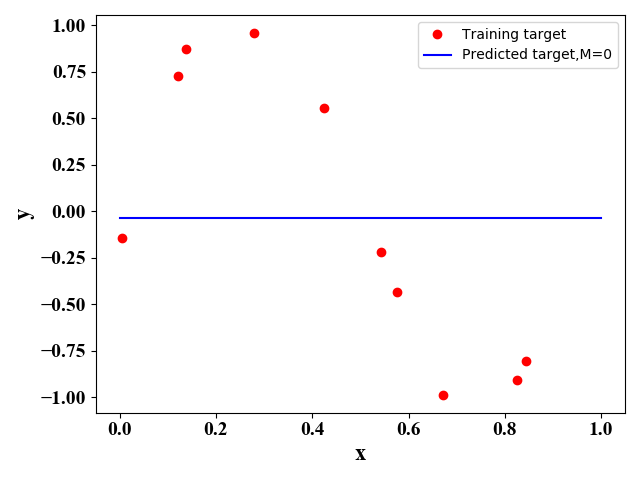 图1
图1 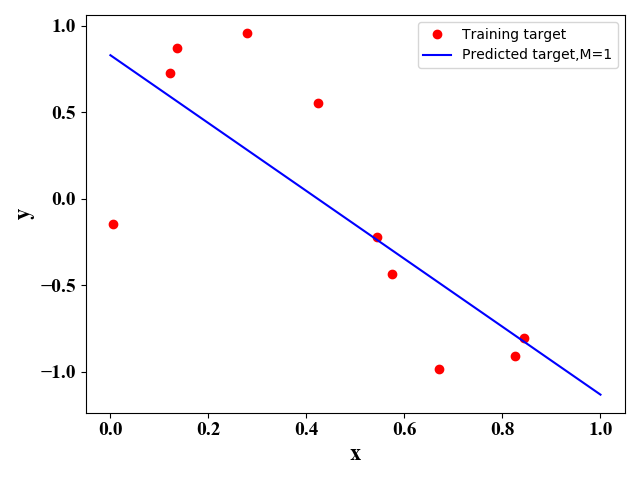 图2
图2 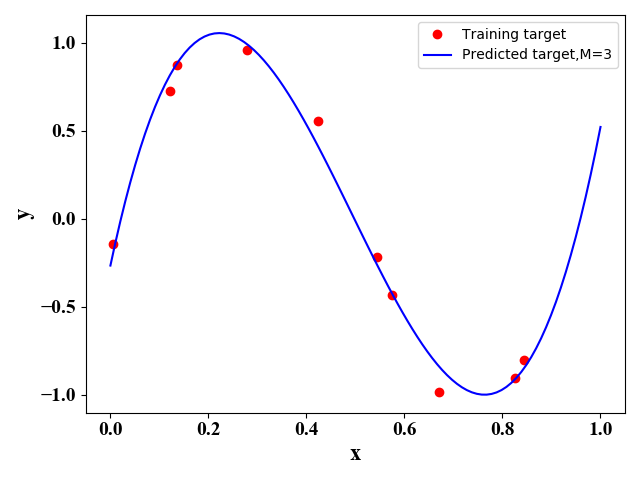 图3
图3 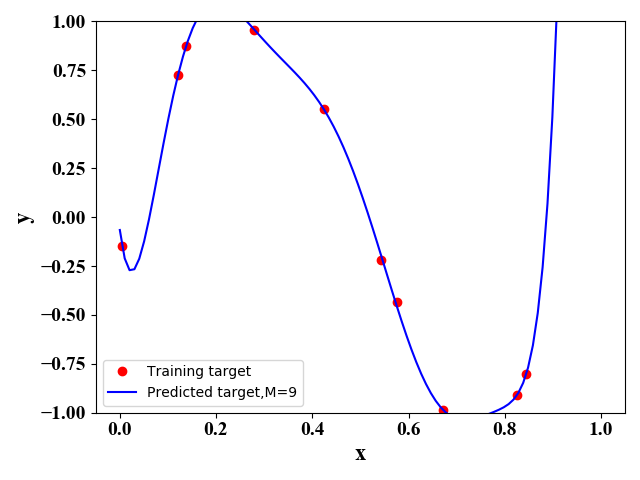 图4
图4 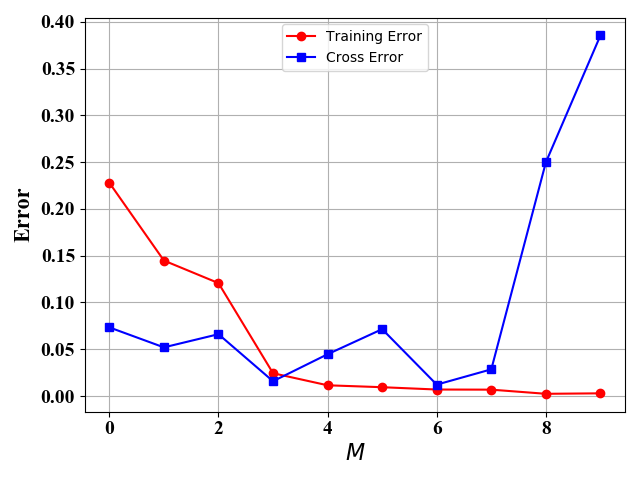 图5 10个训练样例
图5 10个训练样例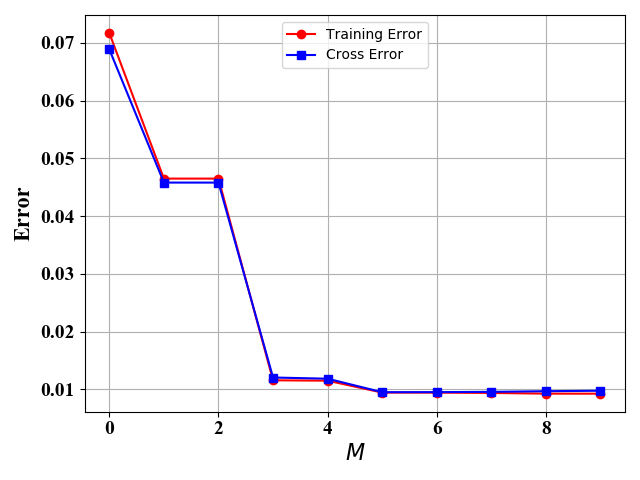 图6 100个训练样例
图6 100个训练样例 图7 50个训练样例
图7 50个训练样例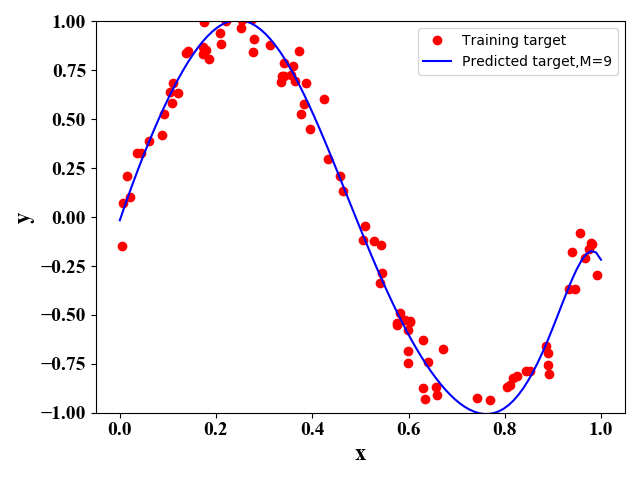 图8 100个训练样例
图8 100个训练样例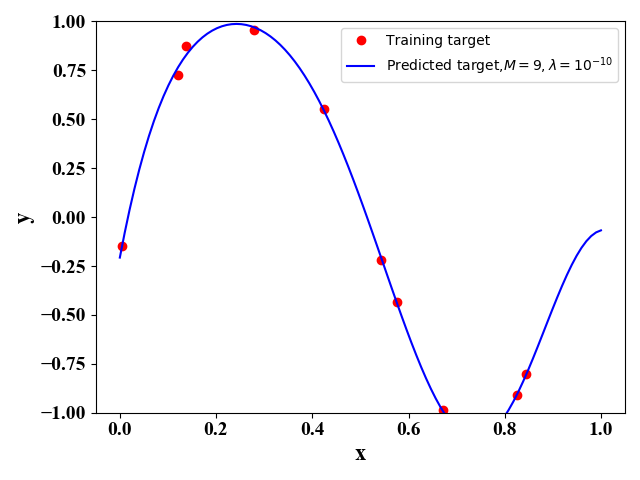 图9
图9 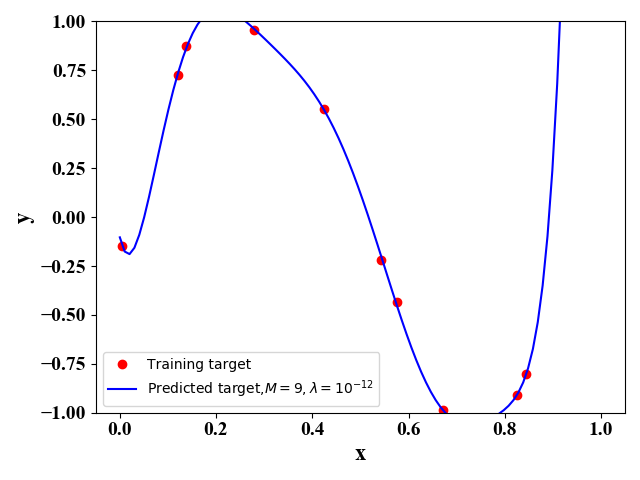 图10
图10 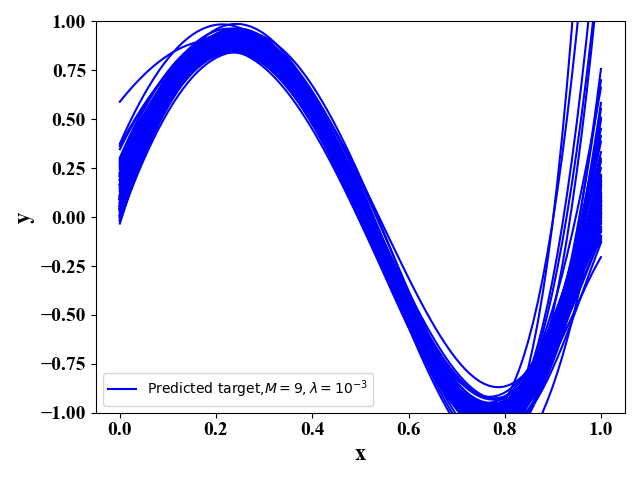 图11
图11 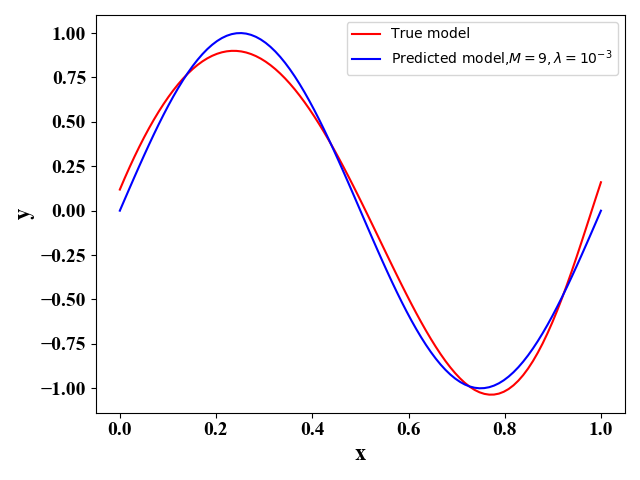 图12
图12  图13
图13 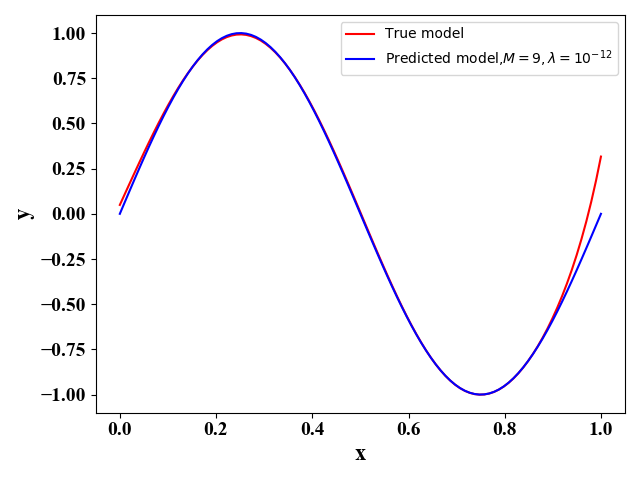 图14
图14 
